
< VoiceFilter > Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
in Study on Source Separation, Voicefilter
소개
- 이 글은 논문을 읽고 정리하기 위한 글입니다.
- 내용에 오류가 있는 부분이 있다면 조언 및 지적 언제든 환영입니다!
[1] Interspeech 2019 에 올라온 논문입니다. (Paper, github github2, youtube)
Citation
@misc{wang2019voicefilter,
title={VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking},
author={Quan Wang and Hannah Muckenhirn and Kevin Wilson and Prashant Sridhar and Zelin Wu and John Hershey and Rif A. Saurous and Ron J. Weiss and Ye Jia and Ignacio Lopez Moreno},
year={2019},
eprint={1810.04826},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
Introduction
- Background
- Automatic Speech Recognition(ASR) 은 noisy 하고 먼 음성 조건에도 성능 향상을 이뤘다.
- 하지만, 여러 명의 화자가 말하는 환경 즉
Cocktail Party Problem에서는 상당한 ASR 성능 감소가 존재한다.- 이를 위해서
Multi-channel blind separation과Single-channel blind separation측면이 있다.Multi-channel blind separation
- 각 Multi-channel의 화자 방향 에너지 정보 같은 것을 이용하는 방법
Single-channel blind separation
- 단일 채널로 화자의 고유 특징을 이용한 분리를 진행한다.
- ex) 이전 single-channel blind separation
Deep clustering,Deep attractor network,Permutation invariant training(2018년 기준)Conv-tasnet,DualPathRNN,Wavesplit,SepFormer등, Dilated convolutional layer, Transformer를 이용하여 연구가 진행 되고 있다.
- Limitation
- 기존 classical speech separation task 에 limitation은 다음과 같다.
- 1)
Unknown number of speakers
- 실제 상황에서 몇 명의 화자가 등장하는지 알 수 없다.
- 2)
Permutation problem
- Permutation Invariant training (PIT)과 같은 학습 방법이 필요 할 수 있다. 이는 학습 속도를 느리게 한다.
- 3)
Selection from multiple outputs
- Target Speaker Separation 과 같은 경우, 분리된 여러 화자 중 원하는 Target 화자를 찾기 위한 추가적인 작업이 필요하다.
- Main Proposal 요약
- VoiceFilter 는
Single-channel blind separation으로 Reference Speaker인특정 Target 화자 만을 입력 음원에서 분리하는 것을 목표한다.- 1)
speaker-discriminative embeddings
- Target 화자의 특성을 화자 인식으로 학습된 네트워크의 출력 Embedding 을 추가로 네트워크 입력으로 주었다.
- 이 중 LSTM 기반 화자 인식 모델인
d-vector V2를 사용하였다.- 기존 화자 인식 데이터와 화자 분리를 위한 데이터는 다르기 때문에, 화자 인식으로 pre-trained 한 d-vector를 사용하였다.
- 2)
End-to-End training
- Target speaker로 별도의 Permutation Training 없이 End-to-End 학습을 이뤄냈다.
- clean 과 enhanced signal 간에
power-law compressed reconstruction error를 적용하여 학습을 했다.- 3) Word Error Rate(WER)과 Source-to-distortion ratio(SDR) 성능 평가
- SDR 성능 뿐 아니라, Noisy 상황에 따른 ASR 성능인 WER 결과를 비교하였다.
- 4) Dilated Convolutional layer
- low-level acoustic feature를 효과적으로 잡아내는 Dilated Convolutional layer를 도입했다.
- 5) Dataset generation
- Librispeech 데이터 셋을 이용한 Target Speaker Separation 데이터 셋 생성 방법을 제안한다.
Proposed Method
Method
- Intro
- Single-channel 기반 Reference(Target) 화자에 대한 화자 분리를 네트워크를 제안한다.
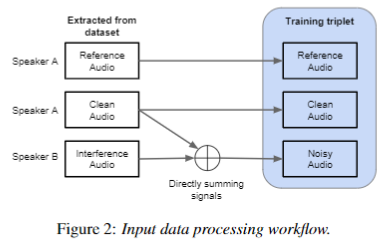
- 3가지 입력:
Reference Audio,Clean Audio,Noisy Audio
Reference Audio: Target Speaker 의 음성만이 담긴 음원 데이터Clean Audio: Target Speaker와 동일한 화자의 음성이 담긴 음원 데이터Noisy Audio:Clean Audio, 다른 화자 목소리와 잡음이 섞인 음원 데이터- 본 System은 크게
Speaker encoder와VoiceFilter system으로 나뉜다.Speaker encoder
Reference Audio를 입력으로 받아, Target 화자에 대한 화자 특성 정보를Speaker encoder로 부터 생성한다.VoiceFilter system
- 두
Noisy Audio와Speaker encoder의 출력 embedding를 입력으로 받아 enhanced magnitude spectrogram를 위한 soft mast를 구해낸다.
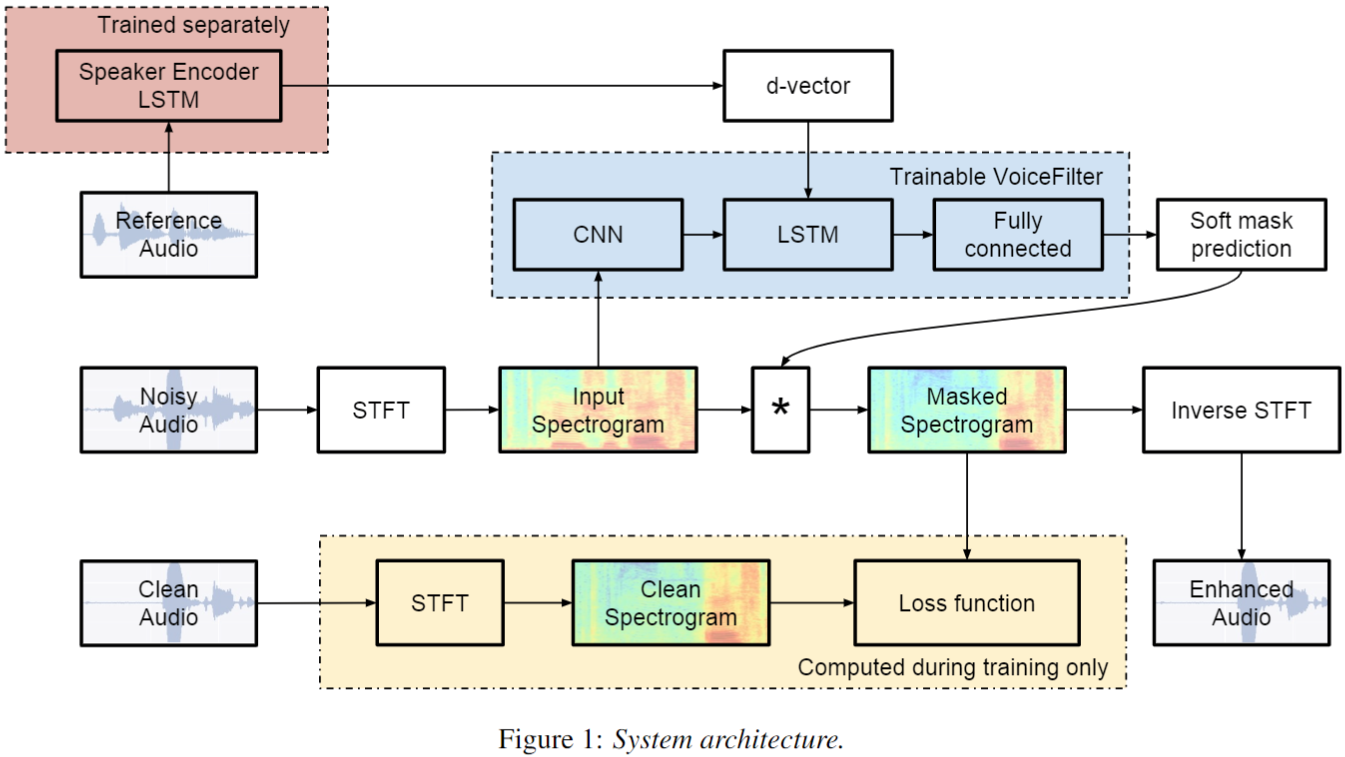
- Architecture
- 1) Speaker encoder, d-vector V2:
ref input -> 1 x 256
- 1.1) log-mel Feature:
T' x 40
- STFT: window size (25ms), hop size (10ms)
- 40-dimension log-mel-filterbank energies
- 1.2) Chunking:
T x 40
- d-vector 입력을 위한 Chunking 작업
- Input Length: 1600ms (160 개)
- Step Size: 50% overlap, 800ms (80 개)
- 1.3) d-vector V2:
T x 40 -> T x 768
- 1.3.1) 3-layer LSTM:
T x 40 -> T x 768
- 각 Frame 에 대한 Embedding 생성
- 1.3.2) Projection Embeddings:
T x 768 -> T x 256
- 더 작은 차원으로 embedding projection
- 1.3.3) L2 norm:
T x 256 -> T x 256
- 각 Frames 에 생성된 Embedding 에 대해 channel 성분 L2-normalization 적용
- 1.3.4) Average Embeddings:
T x 256 -> 1 x 256
- 각 시간에 나온 embedding 들 평균하여 d-vector embedding 생성
- 2) VoiceFilter System:
Noisy Spectrogram + speaker encoder output(1 x 256) -> soft-mask for Noisy Spectrogram
- 2.1) STFT: Input - Noisy Audio and Clean Audio (3 seconds)
input -> 1 x T x 601
- window size: 25ms, hop size (10ms)
- Sample rate: 16kHz
- num frequency: 601 (n_fft: 1024), n_fft//2 + 1 = 601
- half-freq aliasing (n_fft//2), and
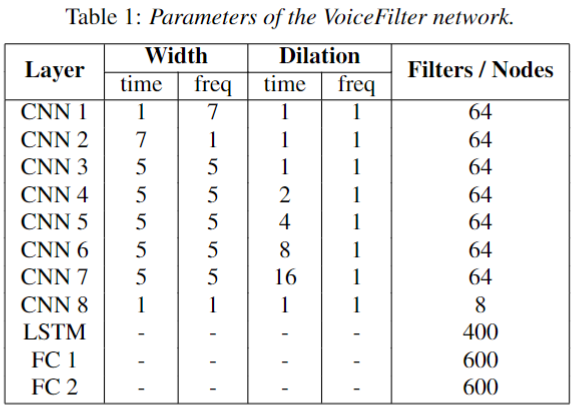
+ 1means power frequency bin- 2.2) CNN:
1 x T x 601 -> T x (8 x 601)
- 2.2.1) 8 convolutional layers
- 2.2.2) Transpose and squeeze:
8 x T x 601 -> T x D(8 x 601)
- Transpose:
8 x T x 601 -> T x 8 x 601- squeeze:
T x 8 x 601 -> T x D(8 x 601)- 2.3) Repeatedly concatenated speaker embedding:
1 x 256 -> T x 256
- 2.3.1) Repeat:
1 x 256 -> T x 256
- d-vector 출력을 noisy의 Time frame 수 만큼 repeat한다.
- 2.3.2) concatenate:
[T x D, T x 256](dim=1) -> T x (D + 256)
- Concat d-vector and CNN outputs
- 2.4) 1-layer Bi-LSTM + relu:
T x (D + 256) -> T x (400 x 2)- 2.5) 2-layer FC:
T x 800 -> T x 601
- 2.5.1) First layer FC + relu:
T x 800 -> T x 600- 2.5.2) Second layer FC + sigmoid:
T x 600 -> 601
Experiments Result
Dataset
- Dataset 1)
Speaker encoder
- MultiReader 라는 technique 를 이용하여 2개의 dataset를 합쳤다.
- small dataset과 large dataset이 존재한다고 할때, small 데이터 셋에 대해서 좋은 성능을 가지도록 하면서 large dataset를 잘 이용하여 학습하는 방법
- large dataset을 regularization 과 같이 사용하는 방법
- 자세한 내용은 논문 참고
- First dataset
- mobile 과 farfield 기기, 영어로 구성된 데이터
- 34 million utterance, 138 thousand speakers
- Second dataset
- LibriSpeech, VoxCeleb, VoxCeleb2
- Dataset 2)
VoiceFilter system
- 기존 Speech separation 벤치마크 데이터 셋은 사용할 수 없었다. (ex. CHIME)
- 이는 target speaker 를 위한 clean한 reference utterance 가 별도로 존재하지 않았기 때문이다.
- 본 논문에서는 Librispeech 를 이용하여 데이터 셋을 직접 생성했다.
- VCTK dataset (small Librispeech dataset)
- Train와 Test 데이터 생성을 위해서 Libirspeech 데이터에서 각각 99명, 10명 화자만을 이용한 small dataset를 생성했다.
- 모델을 빠르게 실험해보고 작은 데이터 셋에 대해서도 VoiceFilter가 효과적으로 작동함을 보이려 했다.
- Librispeech dataset (Large dataset)
- Train와 Test 데이터 생성을 위해서 Libirspeech 데이터에서 각각 2338명, 73명의 화자를 이용하여 큰 데이터 셋을 만들었다.
- 100k 만큼의 triplet 데이터를 생성하였다. (triplet: Reference Audio, Clean Audio, Noisy Audio 세트)
Data Generation
- 데이터 생성 알고리즘
- 1) Randomly Choose reference audio
- 모든 발화 중에서 랜덤으로 한 개를 선택한다.
- 2) Picked the Clean Audio
- reference audio에서 선택된 화자의 발화 중, 이미 선택된 발화를 제외한 나머지 발화 중 랜덤으로 한 개를 선택한다.
- 3) Randomly Choose Interfering Audio
- 이미 선택된 화자 이회의 모든 발화 중 랜덤으로 한 개의 발화를 선택한다.
- 4) Generate Noisy Audio
- Clean Audio와 Interference Audio 를 단순히 Summation 하여 Noisy Audio를 생성한다.
- Summation할때, Interference Audio 크기를 조절하는 trimming 기법을 적용했다.
- trimming은 단순이 목소리 크기를 조절하기 위해서 단순히 어떤 값을 곱한 뒤에 더하는 방법이다.
- 여기서는 (0,1) 또는 (0,2)사이의 값을 random sampling 후 interference Audio에 곱하여 interference Audio 크기를 조절했다.
- (0,1) 과 (0,2) 간에 성능 차이는 없었다고 한다.
Training Strategy
- 논문에 딱히 내용이 없다. github 기준으로 설명하겠다.
- Batch size: 8
- optimizer: Adam
- Adabound:
- initial: 0.001
- final: 0.05
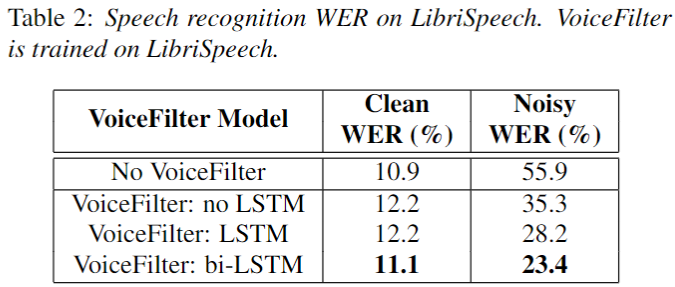
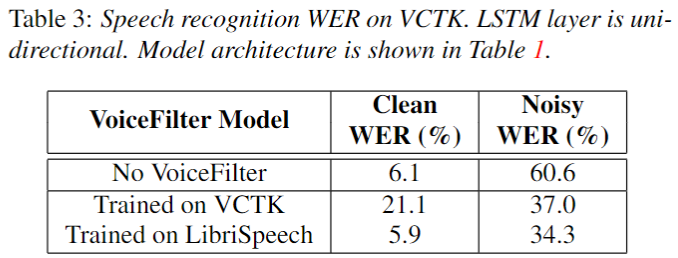
Results: Word error rate(WER)
- 4종류 음원에 대해서 WER를 측정하였다.
- 1) Clean WER: Without VoiceFilter, WER on the clean audio
- 2) Noisy WER: Without VoiceFilter, WER on the noisy audio (mixed)
- 3) Clean-enhanced WER: With VoiceFilter, WER on the clean audio
- 2) Noisy-enhanced WER: With VoiceFilter, WER on the noisy audio (mixed)
- 결론: LibriSpeech dataset
- Clean Audio에 대해서는 VoiceFilter를 적용하지 않는 것이 좋았다.
- Noisy Audio에 대해서 굉장한 성능을 보였다.
- speaker encoder의 화자 인식 정보는 많은 성능 향상을 주었다.
- bi-LSTM 이 가장 좋은 성능을 보였다.
- 결론: VCTK dataset
- 흥미롭게도, VCTK 와 같이 작은 데이터 셋으로만 학습하여도 Noisy Audio에 대해서 큰 성능 향상을 이룰 수 있었다.
- 하지만, VCTK 같은 경우 Clean 상황에 대해서 많은 성능 감소 현상을 보였다.
- 큰 데이터 셋인 Librispeech로 학습한 경우 Clean WER에 대해서도 좋은 성능을 보였으며, Noisy WER 성능도 소폭 상승했다.
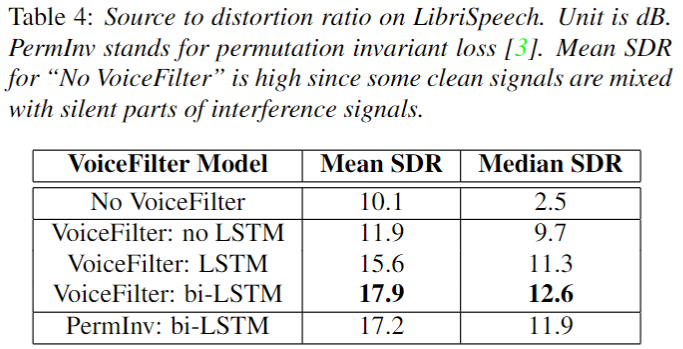
Results: Source to distortion ratio (SDR)
- WER 결과와 동일하게, bi-LSTM 구조에서 좋은 성능을 보였다.
- 추가로 Permutation Invariant Training 기반에 학습 보다 VoiceFilter가 더 뛰어난 성능을 보였다.
Conclusion
- Target Speaker 기반 Source Separation 으로 Permutation Invariant Training 과 같은 방법 없이 효과적으로 학습했고 성능도 뛰어났다.
- Speaker-discriminative embeddings 를 이용하여, Target 화자를 효과적으로 분리하였다.
- Target Speaker 학습을 위한 데이터 생성 방법을 제안했다.
- Automatic Speech Recognition 관점에서 noisy 상황에 대해서 굉장한 성능 향상을 보였다. 하지만, clean 상황에서는 아직 성능 향상을 보지 못했다.
Future Work
- Enhanced speaker encoder
- 현재 d-vector 이후, x-vector 와 같이 더 뛰어난 성능을 보이는 화자 인식 모델을 도입해 보는 것도 좋을 것 같다. (모델 크기가 커질 것 같긴 하다…)
- Attention mechanism
- Transformer의 Attention이 target speaker에 대해 LSTM보다 좋을 것 같은데 이에 대한 고민이 필요하다. ()
- Online method
- 이를 위한 VoiceFilter-Lite 논문이 나왔으니 추후 리뷰 해보겠다.
- Loss Function and training strategy
- Multi-user
- 등등
